Right-sizing Lambda functions that process files
You’ve probably seen an architecture that looks like this:
How much memory should we allocate to the Lambda function processing files? One approach is to take some sample data and run it through Lambda Power Tuning, but what if we’re processing files of different sizes? The easy way out is to keep increasing the memory until you can safely handle all uploads, but this comes at a cost. Let’s look at how we can choose the right amount of memory for each of our files!
Is it really worth it?
It’s tempting to add functionality like this during the initial development process, but let’s do the maths to understand if we’ll actually get a return on our time investment.
Example 1 - low traffic upload
At one Request Per Second (RPS), we’ll handle somewhere in the region of two and a half million requests per month. If it takes 256 MB of RAM to process most files, and 1024 MB of RAM to process 10% of the files which happen to be larger, our costs are as follows:
-
All invocations at 1024 MB, all taking 3s: $98.67 / month
-
90% invocations at 1024 MB, 10% at 256 MB, all taking 3s: $23.29 / month
That seventy dollar saving does feel nice, but we have to evaluate the developer cost to implement this functionality, and the operational cost of more Lambdas (e.g. using more complex dashboards that show more data).
Example 2 - high traffic upload
At one hundred RPS, the numbers get more interesting:
-
All invocations at 1024 MB, all taking 3s: $3,410.39 / month
-
90% invocations at 1024 MB, 10% at 256 MB, all taking 3s: $10,414.36 / month
How about if the big files are only 1% of the uploads?
-
All invocations at 1024 MB, all taking 3s: $3,410.39 / month
-
99% invocations at 1024 MB, 1% at 256 MB, all taking 3s: $2,710.55 / month
You’ll have to perform your own calculations to decide what makes sense for your context. Let’s see how we can pick the right amount of Lambda memory for our input file size.
Right-sizing Lambda functions
Before we continue: it’s assumed that you understand the size(s) of data that your function will process, and have performed Lambda Power Tuning to find the most cost-effective memory setting for each category. That process might give you a table that looks like this:
| Minimum file size | Maximum file size | Ideal Lambda RAM |
|---|---|---|
| 0 | 100 KB | 256 MB |
| 100 KB | 25 MB | 1024 MB |
| 25 MB | Any | 4096 MB |
The original method of triggering a Lambda function or other event when a file is uploaded to an S3 bucket is to use object notifications, but these don’t let us perform any advanced filtering. In late 2021, AWS released an integration with EventBridge. With that in place, we can create an event rule that routes our object created event to the right place. Here’s what the event looks like:
{
"version": "0",
"id": "2ffe83a5-48ff-fccd-2dda-a57a03c22f4b",
"detail-type": "Object Created",
"source": "aws.s3",
"account": "123456789012",
"time": "2023-06-18T19:17:31Z",
"region": "eu-west-1",
"resources": [
"arn:aws:s3:::right-size-lambdas-files"
],
"detail": {
"version": "0",
"bucket": {
"name": "right-size-lambdas-files"
},
"object": {
"key": "large",
"size": 31457280,
"etag": "f6877c498a97505d3a45f485cefc2a40-2",
"sequencer": "00648F584721ECA86B"
},
"request-id": "2JR2MJWXPFG2JME4",
"requester": "123456789012",
"source-ip-address": "123.123.123.123",
"reason": "CompleteMultipartUpload"
}
}
You’ll see that the event contains a size field in bytes. You may have made
an EventBridge rule that looks like this before:
{
"detail": {
"bucket": {
"name": [
"right-size-lambdas-files"
]
}
},
"detail-type": [
"Object Created"
],
"source": [
"aws.s3"
]
}
But we can’t match an exact number of bytes - it’ll be different every time.
Luckily, we can use the numeric operator to match a range. Let’s see what
that looks like for the first entry in our table:
{
"detail": {
"object": {
"size": [
{
"numeric": [
">",
0,
"<=",
100000
]
}
]
}
}
}
The above event rule captures the smallest files with two conditions. The
medium-sized Lambda’s event rule looks nearly identical, just with different
size values, and the large files event rule has only a starting range:
{
"detail": {
"object": {
"size": [
{
"numeric": [
">",
25000000
]
}
]
}
}
}
It’ll capture all files over 25 MB.
We can update our architecture diagram to indicate that we’re choosing the right Lambda for the job:
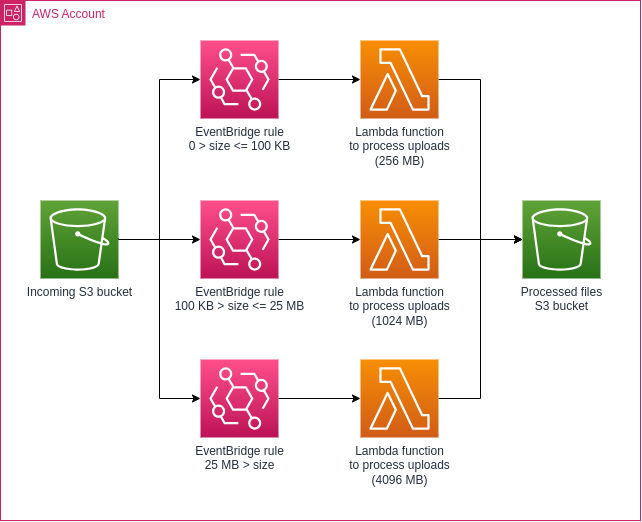
That’s it! Small files go to the Lambda with the least memory, and the biggest files get a full four gigabytes of RAM.
Full working example
You can find a fully working example of this technique on GitHub. It uses exactly the same codebase to create three Lambda functions of different sizes. Give it a try!
Conclusion
At high volumes, it can make sense to route files to an appropriately sized Lambda function. This doesn’t replace Lambda Power Tuning however - we still want to find the most cost-effective memory setting for each group of files we want to process.
With EventBridge, we can filter on ranges of numeric values. This lets us send the right S3 object created event to the appropriate Lambda, with no changes to our Lambda code!